
New Attack Technique ‘Sleepy Pickle’ Targets Machine Learning Models
The security risks posed by the Pickle format have once again come to the fore with the discovery of a new “hybrid machine learning (ML) model exploitation technique” known as Sleepy Pickle. The attack method, per Trail of Bits, weaponizes the very common format used to package and distribute machine learning (ML) models to corrupt the model itself, posing a severe supply chain risk to an organization’s downstream customers. “Sleepy Pickle is a stealthy and novel attack technique that targets the ML model itself rather than the underlying system,” security researcher Boyan Milanov said. While pickle is a widely used serialization format by ML libraries like PyTorch, it can be used to carry out arbitrary code execution attacks simply by loading a pickle file “We suggest loading models from users and organizations you trust, relying on signed commits, and/or loading models from [TensorFlow] or Jax formats with the from_tf=True auto-conversion mechanism,” Hugging Face points out in its documentation.
ATTACK OVERVIEW:
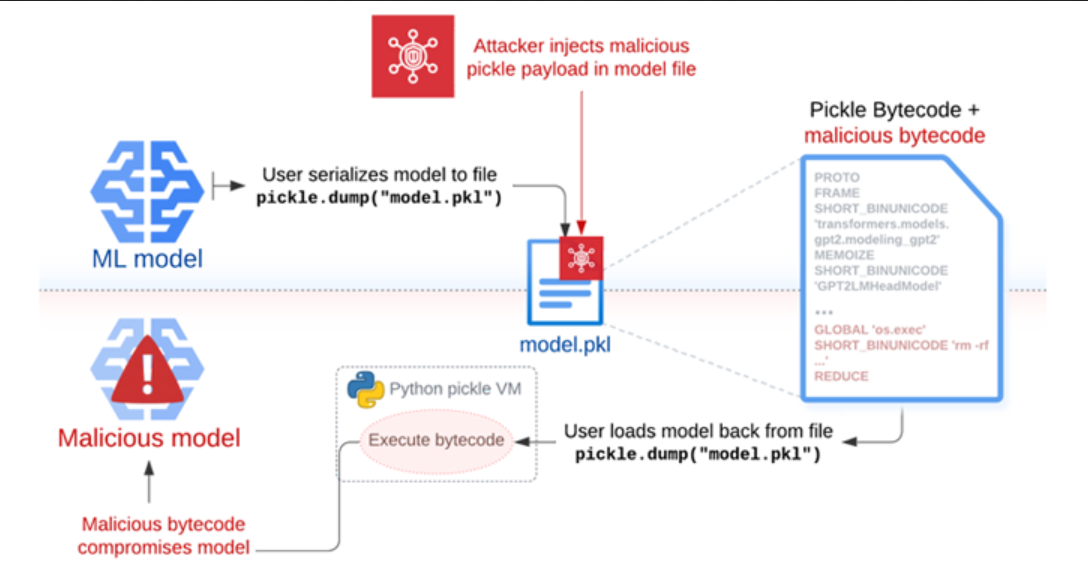
Sleepy Pickle works by inserting a payload into a pickle file using open-source tools like Fickling, and then delivering it to a target host by using one of the four techniques such as an adversary-in-the-middle (AitM) attack, phishing, supply chain compromise, or the exploitation of a system weakness. “When the file is deserialized on the victim’s system, the payload is executed and modifies the contained model in-place to insert backdoors, control outputs, or tamper with processed data before returning it to the user,” Milanov said. Put differently, the payload injected into the pickle file containing the serialized ML model can be abused to alter model behavior by tampering with the model weights, or tampering with the input and output data processed by the model. In a hypothetical attack scenario, the approach could be used to generate harmful outputs or misinformation that can have disastrous consequences to user safety, steal user data when certain conditions are met, and attack users indirectly by generating manipulated summaries of news articles with links pointing to a phishing page.
ML LIBRARY PyTorch:
PyTorch is an open source machine learning (ML) framework based on the Python programming language and the Torch library. Torch is an open source ML library used for creating deep neural networks and is written in the Lua scripting language. It’s one of the preferred platforms for deep learning research. The framework is built to speed up the process between research prototyping and deployment. The PyTorch framework supports over 200 different mathematical operations. PyTorch’s popularity continues to rise, as it simplifies the creation of artificial neural network models. PyTorch is mainly used by data scientists for research and artificial intelligence (AI) applications. PyTorch is released under a modified BSD license. PyTorch was initially an internship project for Adam Paszke, who at the time was a student of Soumith Chintala, one of the developers of Torch. Paszke and several others worked with developers from different universities and companies to test PyTorch. Chintala currently works as a researcher at Meta (formerly Facebook), which uses PyTorch as its underlying platform for driving all AI workloads.
WORKING OF PyTorch:
PyTorch is pythonic in nature, which means it follows the coding style that uses Python’s unique features to write readable code. Python is also popular for its use of dynamic computation graphs. It enables developers, scientists and neural network debuggers to run and test a portion of code in real time instead of waiting for the entire program to be written. PyTorch provides the following key features:
- Tensor computation
- TorchScript
- Dynamic graph computation
- Automatic differentiation
- Python support
- Variable
- Parameter
- Modules
- Functions
WEAPONIZING ML MODELS WITH RANSOMWARE:
The security challenges surrounding pre-trained ML models are slowly gaining recognition in the industry. However, comprehensive security solutions are currently very few and far between. There is still much to be done to raise general awareness and implement adequate countermeasures. In the spirit of raising awareness, how easily an adversary can deploy malware through a pre-trained ML model. The ransom ware sample as the payload instead of the traditional benign calc.exe used in many proof-of-concept scenarios. The reason behind it is simple: Highlighting the destructive impact such an attack can have on an organization will resonate much more with security stakeholders and bring further attention to the problem. Trail of Bits said that Sleepy Pickle can be weaponized by threat actors to maintain surreptitious access on ML systems in a manner that evades detection, given that the model is compromised when the pickle file is loaded in the Python process. This is also more effective than directly uploading a malicious model to Hugging Face, as it can modify model behavior or output dynamically without having to entice their targets into downloading and running them.
“With Sleepy Pickle attackers can create pickle files that aren’t ML models but can still corrupt local models if loaded together,” Milanov said. “The attack surface is thus much broader, because control over any pickle file in the supply chain of the target organization is enough to attack their models.”
“Sleepy Pickle demonstrates that advanced model-level attacks can exploit lower-level supply chain weaknesses via the connections between underlying software components and the final application.”
REMEDIATION STEPS:
- Don’t use pickle in case of an alternative: Following this rule, would help in preventing any pickle attack or pickle exploitation in a user’s computer.
- Use integrity checking mechanisms when sending or receiving files: Implanting unique signatures or watermarks into models. These watermarks can then be checked to validate the model’s authenticity. Runtime Behavior Analysis: By monitoring the runtime behavior of models, any anomalies or deviations can signal potential integrity breaches.
- Submit / evaluate the risk of ML models: To properly evaluate your machine learning models and select the best one, you need a good validation strategyand solid evaluation metrics picked for your problem. A good validation (evaluation) strategy is basically how you split your data to estimate future test performance. It could be as simple as a train-test split or a complex stratified k-fold strategy.
- Never load Sensitive data in untrusted environments: It is a dangerous step as it can lead to massive exploitation with threat actor/attacker gaining access to the user system and inserting of malicious files and stealing of sensitive, important or personal information. Therefore, it is advised not to share or post any sensitive data in unknown or untrusted environments.


